近年来,知识图谱已成为组织和访问不同行业(从医疗保健到工业、银行和保险、零售等)中大量企业数据的重要工具。
知识图谱是一个基于图谱的数据库,它以结构化和语义丰富的格式表示知识。这可以通过从结构化或非结构化数据(例如文档中的文本)中提取实体和关系来生成。在知识图谱中维护数据质量的一个关键要求是将其基于标准本体。拥有标准化的本体通常涉及将此本体纳入软件开发周期的成本。UnmuteAdvanced SettingsFullscreenPauseUp Next
组织可以采用系统的方法生成知识图谱,方法是首先摄取标准本体(如保险风险)并使用大型语言模型 (LLM)(如 GPT-3)创建脚本来生成和填充图数据库。
第二步是使用LLM作为中间层,获取自然语言文本输入并在图上创建查询以返回知识。创建和搜索查询可以根据存储图形的平台进行自定义,例如Neo4j,AWS Neptune或Azure Cosmos DB。
结合本体和自然语言技术
这里概述的方法结合了本体驱动和自然语言驱动的技术来构建一个知识图谱,该知识图谱可以轻松查询和更新,而无需大量的工程工作来构建定制软件。下面我们提供一个保险公司的例子,但这种方法是通用的。
保险业面临着许多挑战,包括需要以高效和有效的方式管理大量数据。知识图谱提供了一种以结构化和语义丰富的格式组织和访问这些数据的方法。这可以包括节点、边和属性,其中节点表示实体,边表示实体之间的关系,属性表示实体和关系的属性。
在保险业使用知识图谱有几个好处。首先,它提供了一种易于查询和更新的组织和访问数据的方法。其次,它提供了一种以结构化和语义丰富的格式表示知识的方法,这使得它更容易分析和解释。最后,它提供了一种集成来自不同来源的数据的方法,包括结构化和非结构化数据。
下面是一个 4 步方法。让我们详细回顾每个步骤。
方法
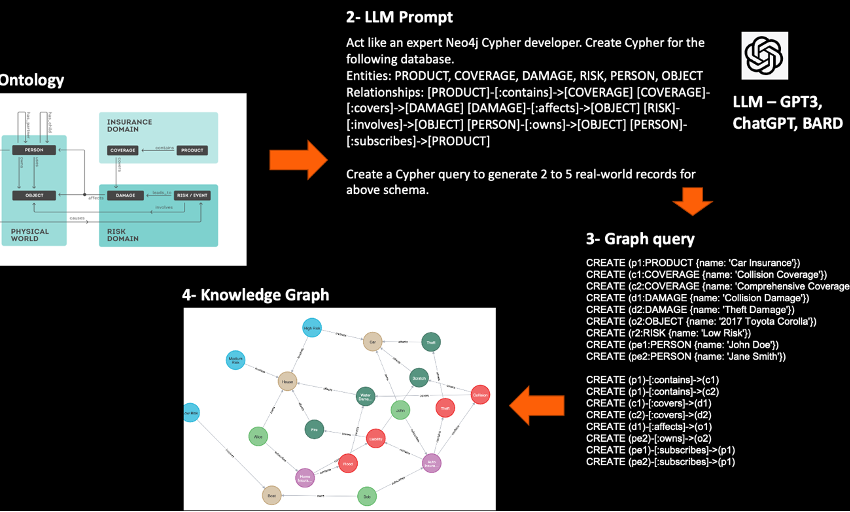
第 1 步:研究本体并识别实体和关系
生成知识图谱的第一步是研究相关的本体,并确定与领域相关的实体和关系。本体是领域内知识的形式表示,包括定义领域的概念、关系和约束。保险风险本体定义了与保险领域相关的概念和关系,例如保单、风险和保费。
本体可以使用各种技术进行研究,包括手动检查和自动化方法。手动检查涉及阅读本体文档并识别相关实体和关系。自动化方法使用自然语言处理 (NLP) 技术从本体文档中提取实体和关系。
确定相关实体和关系后,可以将它们组织到知识图谱的架构中。架构定义图形的结构,包括将用于表示实体和关系的节点和边的类型。
步骤2:为LLM构建文本提示以生成本体的模式和数据库
生成知识图谱的第二步涉及为LLM构建文本提示,以生成本体的模式和数据库。文本提示是本体以及所需架构和数据库结构的自然语言描述。它充当LLM的输入,LLM生成用于创建和填充图形数据库的Cypher查询。
文本提示应包括对本体的描述、步骤 1 中标识的实体和关系以及所需的架构和数据库结构。描述应该是自然语言,并且应该易于LLM理解。文本提示还应包括架构和数据库的任何约束或要求,例如数据类型、唯一键和外键。
例如,保险风险本体的文本提示可能如下所示:
“为保险风险本体创建一个图形数据库。每个策略都应具有唯一的 ID,并且应与一个或多个风险相关联。每个风险都应该有一个唯一的ID,并应该与一个或多个保费相关联。每个保费应具有唯一的ID,并应与一个或多个保单和风险相关联。数据库还应包括确保数据完整性的约束,例如唯一键和外键。
文本提示准备就绪后,可以将其用作LLM的输入,以生成用于创建和填充图形数据库的Cypher查询。
步骤 3:创建查询以生成数据
生成知识图谱的第三步涉及创建 Cypher 查询以生成图形数据库的数据。查询是使用在步骤 2 中创建的文本提示生成的,用于使用相关数据创建和填充图形数据库。
Cypher 查询是一种声明性语言,用于创建和查询图形数据库。它包括用于创建节点、边和它们之间的关系的命令,以及用于查询图形中的数据的命令。
在步骤 2 中创建的文本提示用作 LLM 的输入,LLM 根据所需的架构和数据库结构生成 Cypher 查询。LLM使用NLP技术来理解文本提示并生成查询。
查询应包括为本体中的每个实体创建节点的命令,以及用于表示它们之间关系的边。例如,在保险风险本体中,查询可能包括用于为保单、风险和保费创建节点的命令,以及用于表示它们之间关系的边缘的命令。
查询还应包括确保数据完整性的约束,例如唯一键和外键。这将有助于确保图表中的数据一致且准确。
生成查询后,可以执行该查询以使用相关数据创建和填充图形数据库。
引入查询并创建知识图谱
生成知识图谱的最后一步涉及引入 Cypher 查询和创建图数据库。查询使用在步骤 2 中创建的文本提示生成,并执行以使用相关数据创建和填充图形数据库。
然后,可以使用数据库来查询数据和提取知识。图形数据库是使用图形数据库管理系统(DBMS)创建的,如Neo4j。步骤 3 中生成的 Cypher 查询将引入到 DBMS 中,从而在图形数据库中创建节点和边。
创建数据库后,可以使用Cypher命令对其进行查询以提取知识。LLM还可以用作中间层,以获取自然语言文本输入并在图上创建Cypher查询以返回知识。例如,用户可能会输入诸如“哪些策略具有高风险评级?”之类的问题,LLM可以生成Cypher查询以从图形中提取相关数据。
知识图谱也可以在新数据可用时更新。可以修改 Cypher 查询以包含新节点和边,并且可以将更新的查询引入图形数据库以添加新数据。
这种方法的优点
标准化
摄取标准本体(如保险风险本体)为标准化图中知识的表示提供了一个框架。这样可以更轻松地集成来自不同来源的数据,并确保图形在语义上保持一致。通过使用标准本体,组织可以确保知识图谱中的数据是一致和标准化的。这样可以更轻松地集成来自多个来源的数据,并确保数据具有可比性和意义。
效率
使用 GPT-3 生成用于创建和填充图形数据库的密码查询是自动化该过程的有效方法。这减少了构建图形所需的时间和资源,并确保查询在语法和语义上是正确的。
直观的查询
使用LLM作为中间层来获取自然语言文本输入并在图上创建Cypher查询以返回知识,使查询图更加直观和用户友好。这减少了用户对图形结构和查询语言有深入理解的需要。
生产力
传统上,开发知识图谱涉及定制软件开发,这可能既耗时又昂贵。通过这种方法,组织可以利用现有的本体和NLP工具来生成查询,从而减少对自定义软件开发的需求。
这种方法的另一个优点是能够在新数据可用时更新知识图谱。可以修改 Cypher 查询以包含新节点和边,并且可以将更新的查询引入图形数据库以添加新数据。这样可以更轻松地维护知识图谱,并确保其保持最新性和相关性。
椰有料原创,作者:小椰子啊,转载请注明出处:http://www.studioyz.com/1892.html
文章评论